计算与存储分离 解锁数据处理与存储服务的新范式
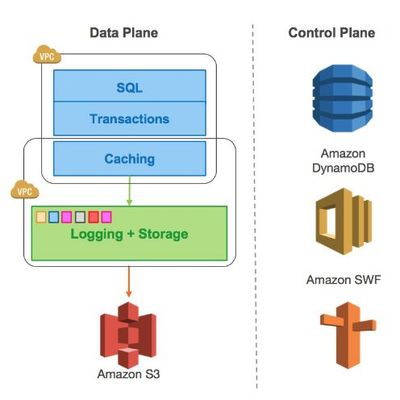
在数字化转型的浪潮中,数据处理和存储服务正经历着一场深刻的架构变革。计算与存储分离(Compute-Storage Separation)作为一种新兴的设计范式,正逐渐成为构建高效、弹性、可扩展数据平台的核心思想。它不仅重塑了数据处理流程,更深刻影响着数据服务的未来形态。
一、核心概念:解耦的力量
计算与存储分离,顾名思义,是将数据计算(数据处理、分析、运算)和数据存储(持久化保存)从传统紧耦合的单一系统中解耦出来,成为两个独立可扩展、可管理的服务层。在传统架构中,如典型的关系数据库,计算节点通常与存储绑定,扩容时往往需要同步增加计算和存储资源,造成资源浪费和灵活性不足。而分离架构允许计算层和存储层根据各自需求独立伸缩,按需付费,显著提升了资源利用率和系统弹性。
二、数据处理服务的革新:从批处理到实时流
在计算与存储分离的架构下,数据处理服务迎来了前所未有的灵活性。计算层可以专门针对不同类型的计算任务进行优化:
- 批处理计算:如Apache Spark、Flink的批处理作业,可以从共享的存储层(如对象存储S3、HDFS)直接读取海量数据,进行计算后,再将结果写回存储。计算集群无需持久化存储数据,任务结束后资源即可释放,极大降低了成本。
- 实时流处理:流处理引擎可以持续消费来自消息队列的数据流,进行实时分析,并将中间状态或最终结果写入独立的存储服务。计算资源的弹性伸缩能力使得系统能够轻松应对流量高峰。
- 交互式查询:如Presto、Trino等引擎,通过分离架构,可以实现对海量数据的即席查询,计算节点作为无状态服务,从统一的数据湖或数据仓库存储中获取数据,查询性能和并发能力得到大幅提升。
三、存储服务的演进:统一、持久与兼容
分离架构中的存储层,承担着数据持久化、高可用、高可靠的核心职责,并呈现出新的特征:
- 统一数据湖存储:以对象存储(如AWS S3、阿里云OSS)为代表,因其极高的持久性、近乎无限的扩展能力和低廉的成本,成为分离架构中存储层的理想选择。它提供了一个统一的数据存储池,供各种计算引擎访问。
- 数据格式与元数据管理:存储层不仅存储原始数据,还通过如Apache Iceberg、Hudi、Delta Lake等表格格式,在存储层面提供了ACID事务、模式演化、时间旅行等高级特性,使得在简单对象存储之上构建企业级数据仓库成为可能。
- 多协议与兼容性:现代存储服务通常提供多种访问协议(如S3、HDFS、文件系统接口),确保各类新旧计算引擎都能无缝接入,保护了现有技术投资。
四、核心优势与价值体现
- 极致弹性与成本优化:计算与存储可独立伸缩。计算资源可按需快速启动和释放,应对波峰波谷;存储资源则根据数据量平滑增长。这种按使用量付费的模式,避免了资源闲置,实现了显著的TCO(总拥有成本)降低。
- 架构简化与运维便利:解耦使得系统组件职责单一,降低了整体架构的复杂性。存储服务的健壮性和持久性由云厂商或专业存储软件保障,计算层可专注于无状态的计算逻辑,运维难度大大降低。
- 数据共享与一致性:所有计算引擎(批处理、流处理、交互式分析、机器学习)都访问同一份存储中的数据,消除了数据孤岛和数据移动拷贝的需要,确保了数据的唯一性和一致性。
- 技术创新加速:计算层和存储层可以独立演进。新的计算框架可以快速利用现有数据资产,存储层也可以持续升级而不影响上层应用,加速了整体技术栈的迭代创新。
五、挑战与考量
尽管优势明显,计算与存储分离的落地也面临一些挑战:
- 网络性能瓶颈:计算节点频繁从远程存储读写数据,网络延迟和带宽可能成为性能瓶颈。解决方案包括数据本地化缓存、计算靠近存储的部署策略(如云上可用区亲和)以及使用高性能网络。
- 数据安全与治理:数据集中存储后,访问控制、加密、审计等安全治理措施需要贯穿整个数据链路,对权限模型和数据策略管理提出了更高要求。
- 生态工具适配:并非所有传统数据处理工具都能天然适配分离架构,可能需要进行改造或选择新的云原生工具。
六、未来展望
计算与存储分离已成为云原生数据架构的基石。随着存算一体芯片、可计算存储、更智能的数据编排调度等技术的发展和融合,未来的数据处理与存储服务将更加智能、高效和无缝。企业构建数据平台时,采纳这一范式,将能更好地应对数据量爆炸性增长、分析需求瞬息万变的挑战,真正释放数据的核心价值。
计算与存储分离不仅仅是一种技术架构选择,更是一种面向云时代的数据管理哲学。它通过解耦带来自由,通过独立扩展实现效率,最终赋能企业构建出更敏捷、更经济、更强大的数据驱动能力。
如若转载,请注明出处:http://www.24zhidao.com/product/59.html
更新时间:2026-06-19 21:47:53