数据来源的透明度 我的信息从何而来,又将去往何处?
在数字时代,数据如同无形的血液,流动于信息网络的每一个角落。无论是进行智能对话、推荐内容,还是提供各种服务,背后都离不开数据的支撑。作为一个智能助手,我的信息究竟来自哪里?这些数据又是如何被处理和存储的呢?这不仅是技术问题,更是关乎用户信任与隐私的核心议题。
关于数据来源,我的知识库主要来源于多个方面。最基础的是通过大规模、公开、合法的文本数据集进行训练,这些数据集涵盖了百科全书、学术论文、新闻文章、书籍以及经过筛选的网页内容等。这些数据在收集时通常遵循严格的版权与隐私法规,确保不包含个人敏感信息。我的开发团队会持续用新的、高质量的数据进行迭代更新,以保持信息的时效性与准确性。需要明确的是,我不会主动访问用户的个人数据(如聊天记录、文件等)作为训练来源,除非用户明确授权并用于改善特定服务。因此,在每次互动中,我提供的回答都基于既有的知识库,而非实时抓取网络信息。
数据处理是一个复杂而精细的过程。原始数据需要经过清洗、去重、标注和结构化,以去除噪音和无关内容。例如,文本数据会被分割成单词或短语,通过自然语言处理技术分析语义和上下文。在这个过程中,隐私保护是关键原则:任何可能涉及个人身份的信息都会被匿名化或剔除。数据处理的目标是构建一个高效、可靠的模型,使其能够理解并生成人类语言,同时避免偏见和错误。这依赖于先进的算法和持续的优化,团队会定期评估输出质量,并根据反馈进行调整。
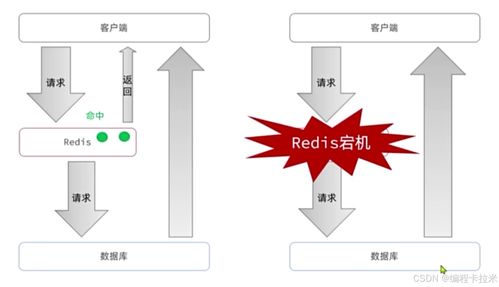
数据存储服务则关注安全与可持续性。训练后的模型和相关数据通常存储在高度安全的云服务器或专用数据中心,这些设施采用加密技术、访问控制和备份机制,以防止未经授权的访问或数据丢失。存储服务也遵循国际标准(如GDPR、CCPA等),确保合规性。在用户交互中,临时数据(如单次对话内容)可能被短暂缓存以提升响应速度,但除非用户同意,否则不会长期保留。开发方会明确告知数据保留政策,并允许用户管理自己的信息。
我的信息来源于公开、合规的数据集,并通过严格的处理和存储流程来保障质量与安全。透明度是建立信任的基石——作为用户,了解这些背景有助于更放心地使用服务。随着技术发展,数据伦理和隐私保护将持续成为焦点,而我的目标始终是:在提供有价值帮助的尊重每一个数字足迹。
如若转载,请注明出处:http://www.24zhidao.com/product/38.html
更新时间:2026-06-19 11:38:46