阿里大神手把手教你画技术架构图 数据处理与存储服务篇

在当今数据驱动的时代,数据处理与存储服务构成了企业技术架构的基石。一个清晰、准确且富有洞察力的技术架构图,不仅是团队沟通的桥梁,更是系统设计与演进的蓝图。本文将以阿里资深架构师的视角,手把手带你绘制一幅专业级的数据处理与存储服务架构图,并深入解析其核心要素与设计精髓。
第一步:明确绘图目标与受众
在动笔之前,首先要问自己:这张图给谁看?是向业务方汇报数据流转全景,还是与开发团队讨论技术选型细节?目标决定了图的详略与视角。对于数据处理与存储服务,通常需要兼顾业务数据流与技术组件两个维度。
第二步:确立核心分层与模块
一个经典的数据处理与存储架构通常可以抽象为以下几层:
- 数据源层:明确数据从何而来。用图标清晰标注各类源头,如业务数据库(MySQL、PostgreSQL)、日志文件、消息队列(Kafka、RocketMQ)、第三方API等。这是整幅图的起点。
- 数据采集与接入层:描绘数据如何被“搬进来”。使用统一的“管道”符号连接数据源与后续层,并标注关键组件,如Flume、Logstash用于日志采集,DataX、Sqoop用于批量同步,Canal用于数据库增量订阅。
- 数据处理与计算层:这是架构的核心“引擎区”。
- 流处理:用闪电符号或流线箭头表示实时计算,标注Flink、Spark Streaming等框架及其上的实时ETL、风控规则计算等任务。
- 批处理:用齿轮或方块表示离线计算,标注Hive、Spark、MaxCompute等平台及其上的数据清洗、聚合、分析作业。
- 在此层,务必用虚线框或泳道图区分开发、测试、生产环境。
- 数据存储层:根据数据形态与服务目的,划分不同的存储区域,这是体现架构师功力的关键。
- 原始数据区/ODS层:存储未经加工的原始数据,可用数据库或HDFS图标表示。
- 数据仓库/DW层:存储经过清洗、整合的主题域数据。用分层图标(如DWD明细层、DWS汇总层)清晰展示。
- 数据湖:如果架构中包含,用湖泊图标表示,用于存储原始格式(如Parquet、ORC)的海量数据。
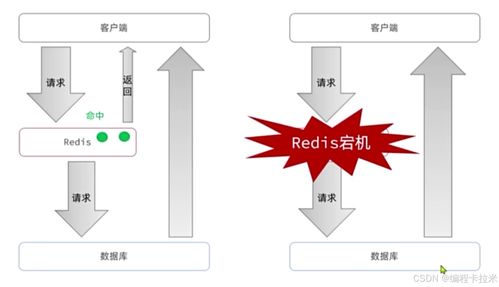
- 在线存储:服务于在线应用的高性能存储,如RDS(关系型)、Tair/Redis(缓存)、表格存储(宽表)、OTS(有序)。用不同的数据库图标区分。
- 数据服务与应用层:数据价值最终在这里体现。描绘数据如何被消费,如通过统一数据服务API、BI报表工具(如Quick BI)、数据大屏、推荐/搜索系统等。
- 运维与治理层:作为支撑,贯穿上下。包括元数据管理、数据质量监控、任务调度(如Airflow、DolphinScheduler)、权限与安全管控。通常在图的一侧或底部以独立模块呈现。
第三步:选择工具与绘图规范
- 工具推荐:专业工具如Draw.io(免费、在线)、Visio、Lucidchart,或代码绘图工具PlantUML、Mermaid(适合版本管理)。阿里内部也广泛使用这些工具或其定制版。
- 绘图规范:
- 一致性:同一类组件使用相同或相似的图形与颜色。例如,所有存储用圆柱体,所有计算用矩形,所有队列用管道。
- 流向清晰:使用带箭头的实线表示主要数据流,虚线表示控制流或低频数据流。流向尽量从左到右、从下到上,符合阅读习惯。
- 关键标注:在连接线上简注数据协议(如HTTP、gRPC)、数据格式(如JSON、Avro)和同步频率(实时、T+1)。在组件旁注明核心技术选型,如HBase vs Cassandra的选型原因。
- 突出重点:对核心链路、新引入组件或存在瓶颈的部分,使用醒目的颜色或外框加以强调。
第四步:绘制与迭代:一个阿里云参考示例
以构建一个典型的实时数据中台存储服务为例:
- 图左侧,画出多个数据源(App日志、业务DB、IoT设备数据)。
- 数据通过DataHub(阿里云流数据总线)或Kafka统一接入,作为“数据高速公路”入口。
- 实时流进入Flink进行实时ETL、聚合计算;批数据通过DataWorks调度MaxCompute进行离线处理。两条链路并行画出。
- 处理后的结果数据,根据用途分流存储:
- 需要实时查询的维度表、用户画像,写入Tair(缓存)和HBase(海量KV)。
- 需要复杂分析的历史明细和聚合结果,写入MaxCompute(数仓)和AnalyticDB(实时分析型数据库)。
- 需要全文检索的数据,写入Elasticsearch。
- 上层通过API网关暴露统一的数据服务接口,供业务应用、BI报表调用。
- 整个流程由DataWorks进行元数据管理、任务调度与数据质量监控。
第五步:附注架构原则与设计思考
一幅优秀的架构图不仅是组件的罗列,更应体现设计思想。在图旁或文档中,补充说明:
- 核心原则:如“分层解耦”、“实时离线一体”、“最终一致性”。
- 关键设计:如为什么选择Lambda架构还是Kappa架构?冷热数据分离策略是什么?
- 容灾与高可用:数据备份、跨可用区部署、故障转移机制如何在图中体现。
- 成本与性能权衡:不同存储选择的成本效益分析。
###
绘制技术架构图是一个不断精炼和抽象的过程。从阿里众多项目的实践来看,一幅好的数据处理与存储架构图,应能让人在3分钟内把握系统全貌,理解数据从哪里来、如何加工、存于何处、谁去使用。它不仅是静态的文档,更应是随着系统迭代而动态更新的“活地图”。记住,清晰的架构图背后,必然是清晰的架构思维。现在,打开你的绘图工具,开始绘制属于你自己的技术蓝图吧!
如若转载,请注明出处:http://www.24zhidao.com/product/37.html
更新时间:2026-06-19 03:41:26